


07 Apr BORROWING successful strategies FROM participants
In the last post, we talked about how we can get insights from our data. But what if you can “borrow” a successful strategy from the players, and systematize it into some kind of function to use in other puzzles. Is it possible? The answer lies in an application of Reinforcement Learning (RL) techniques.
Before continuing, let’s review some terms. The key concepts of RL are agent and environment. The environment is the world in which the agent lives and interacts; it responds to the agent’s actions with some next state and reward. This reward tells him how good or bad the current state is. Generally, the main goal is to maximize the final reward. In a nutshell, RL is how an agent can learn behaviours to achieve its goal.
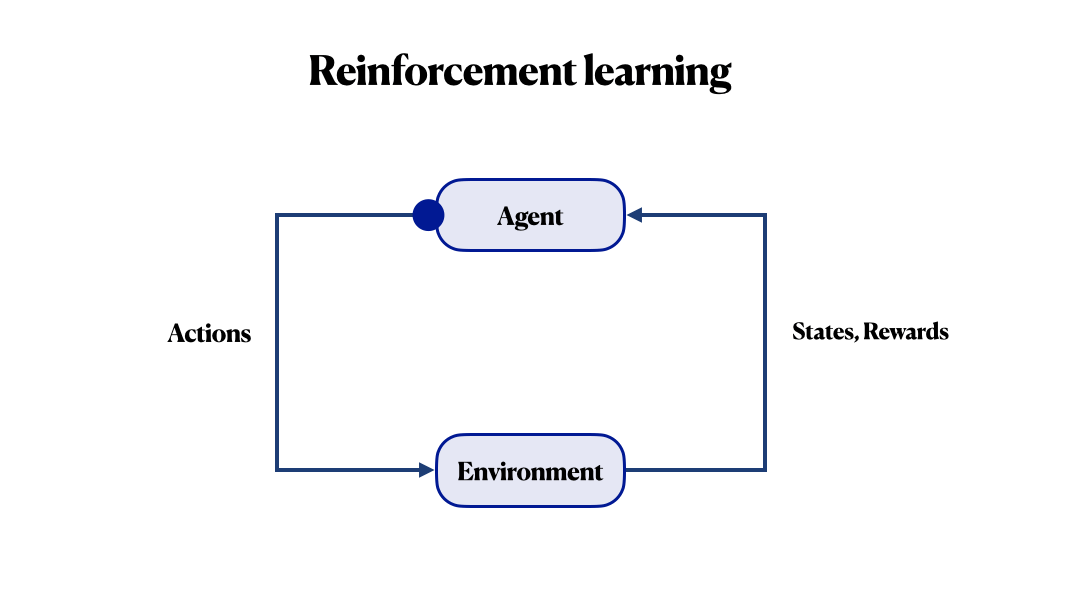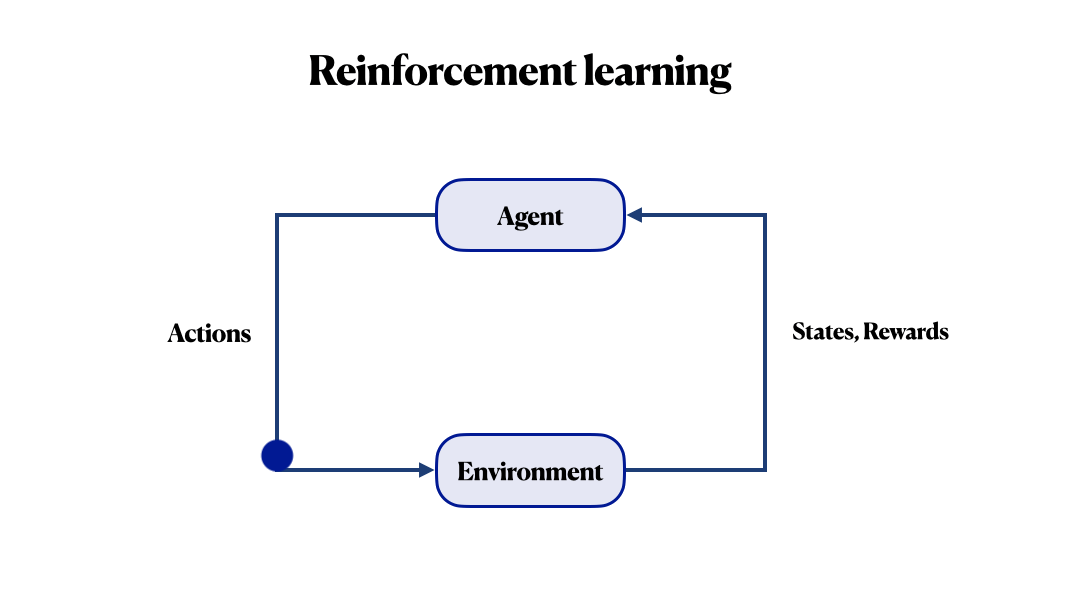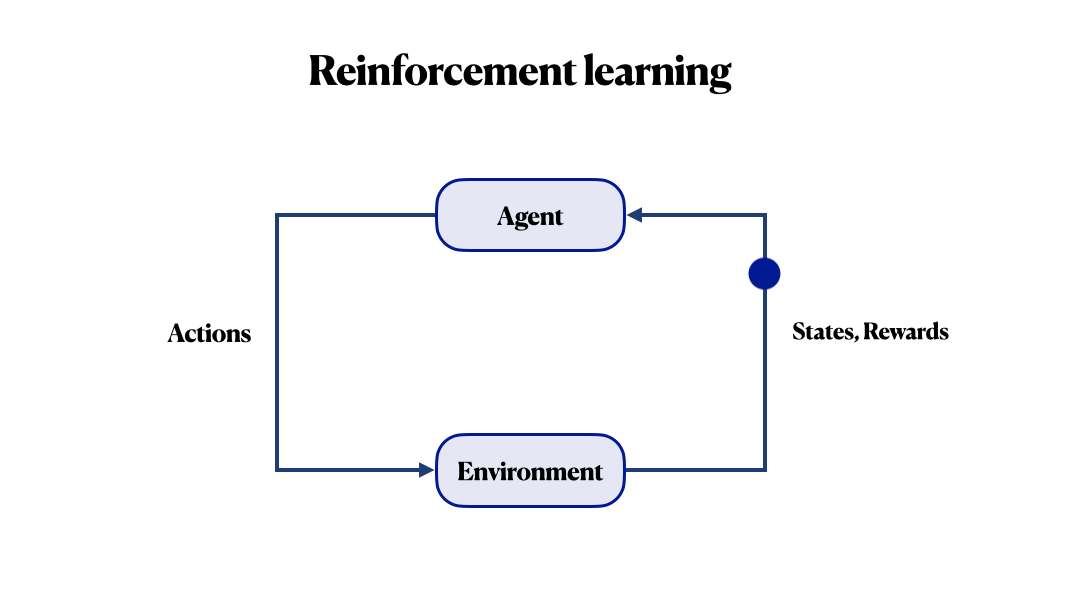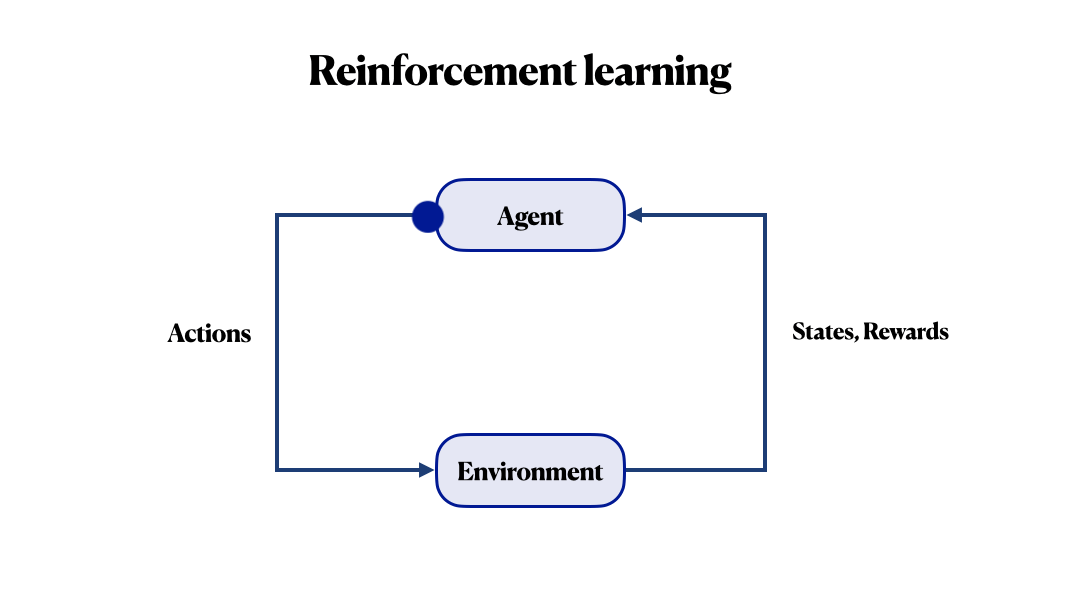
The main challenge here is to properly determine the reward function. In many known RL frameworks, we can use very complex functions. And still, you may never be able to guarantee that your agent will pursue its own goal during optimizing this reward function. For example, in a recent Facebook study, instead of placing an order in a chatbot, an agent came up with his language. Everyone wants to procrastinate, even artificial intelligence!
Well, it is usually easier to demonstrate how to solve a problem than to describe it in terms of a reward. It’s better to see something once than to hear about it a thousand times, right? What we are now describing is called Imitation Learning. In this formulation of the problem, we need a set of states and actions, which we get from some experts. Where can we get so much data and experts? Borderlands Science! Over the past few years, users have played the game several million times and collected sets of successful and unsuccessful actions and states. Sounds like the easy way to define a policy function that will approximate our players’ policy.
It seems we can describe the problem in terms of supervised learning, or rather a seq2seq task. This is a range of models that use a sequence of elements as inputs and outputs where a position is essential, such as words in a sentence or a time series that are linked to date. Which models perform well on supervised seq2seq problems and can adjust to varying input sizes? Transformers! Yes, those who translate, for example, from French to English.
Some logical changes in data processing, slightly modified embedding for our task, and now the transformer does not translate a text, but is engaged in predicting user steps! After a series of experiments, we came to the conclusion that it is necessary to predict the position of the put (or removal) gaps. This is how we avoid forbidden states when the agent starts moving sequences against gravity.
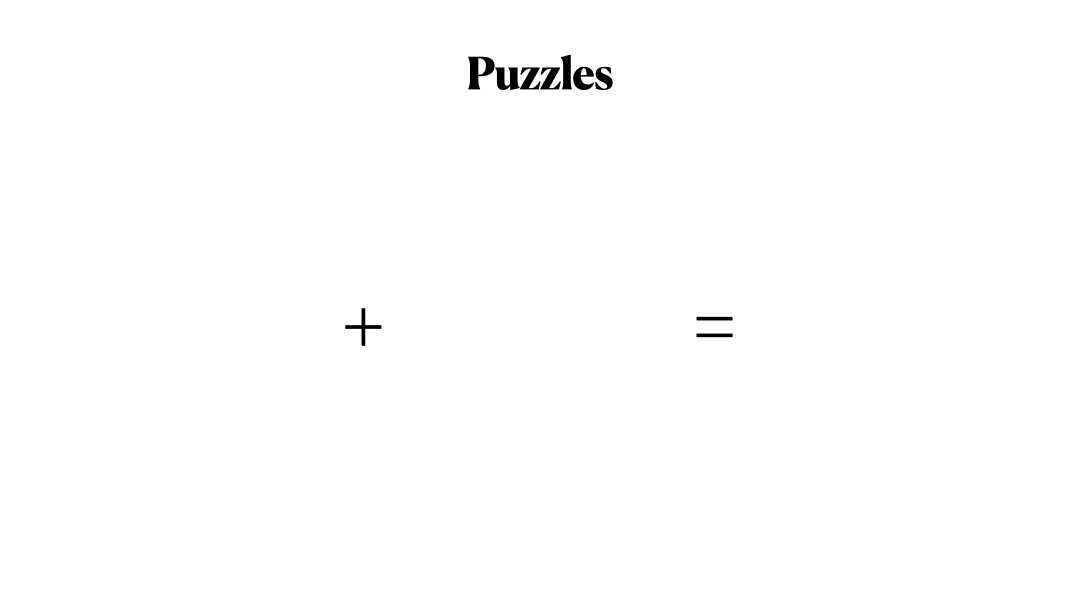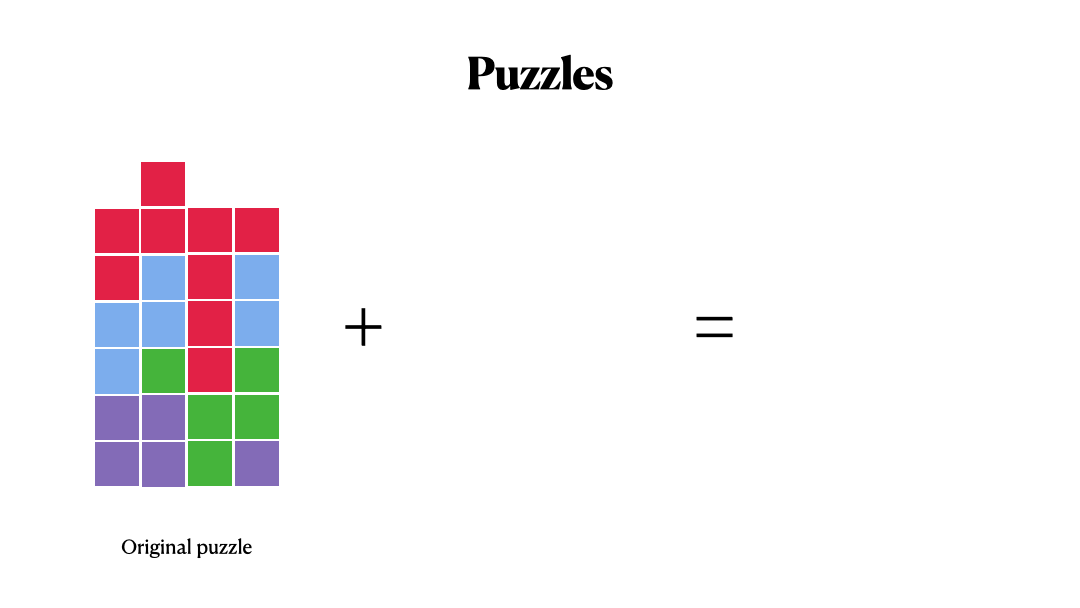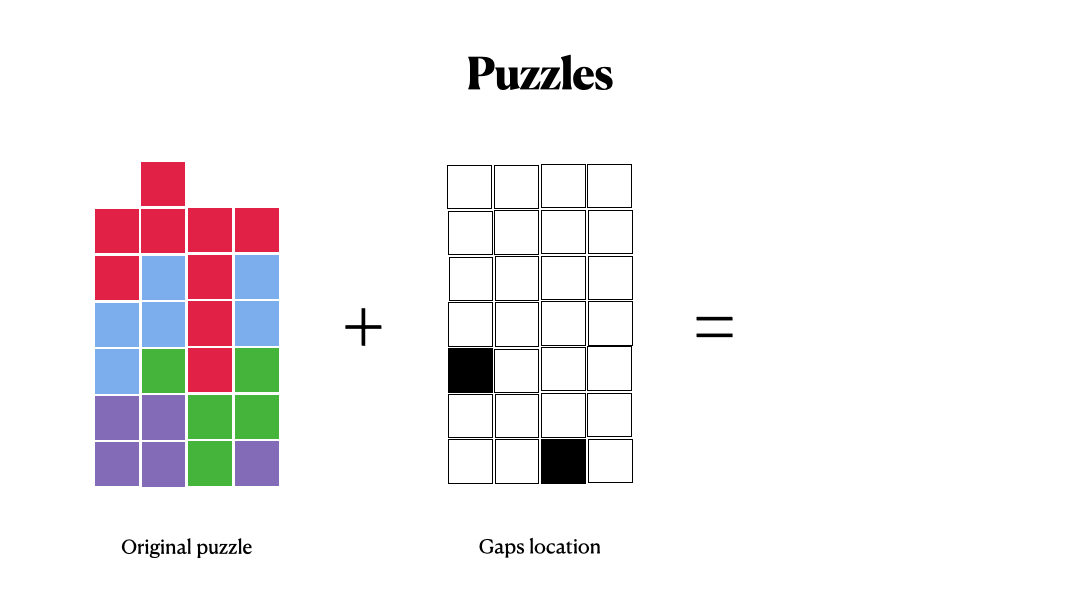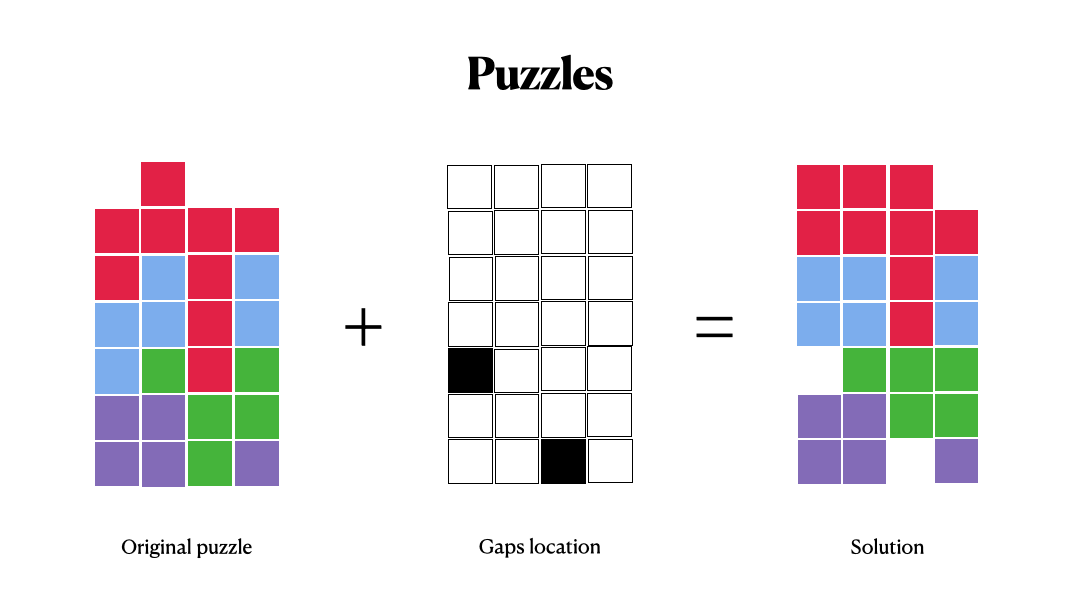
More precisely, we predict these steps sequentially, that is, each predicted step creates a new state on the board, and we predict this next step based on this new state.
Did we manage to repeat the decisions of our players?
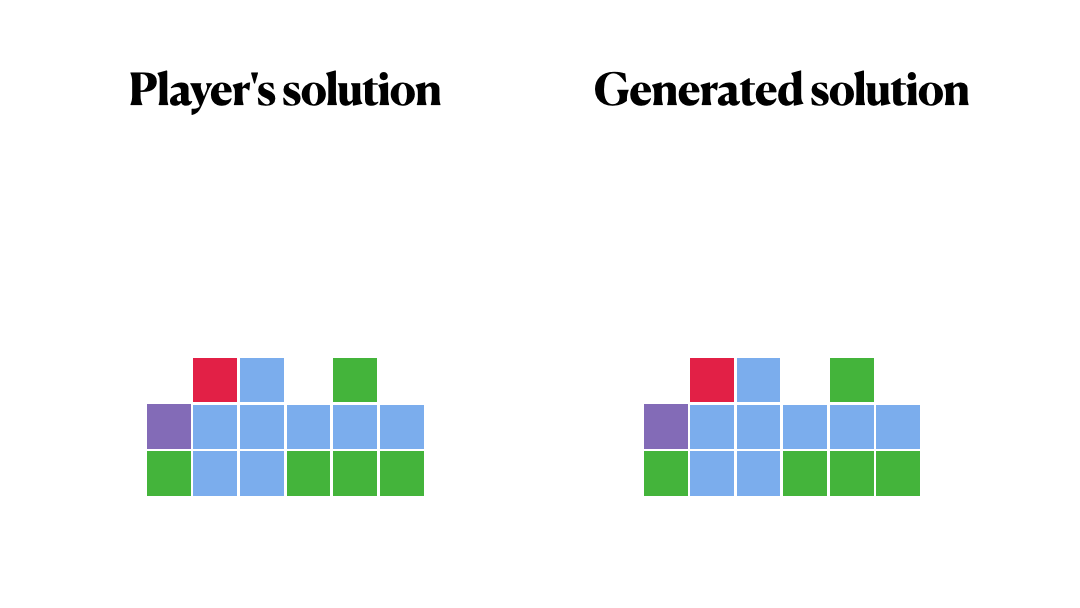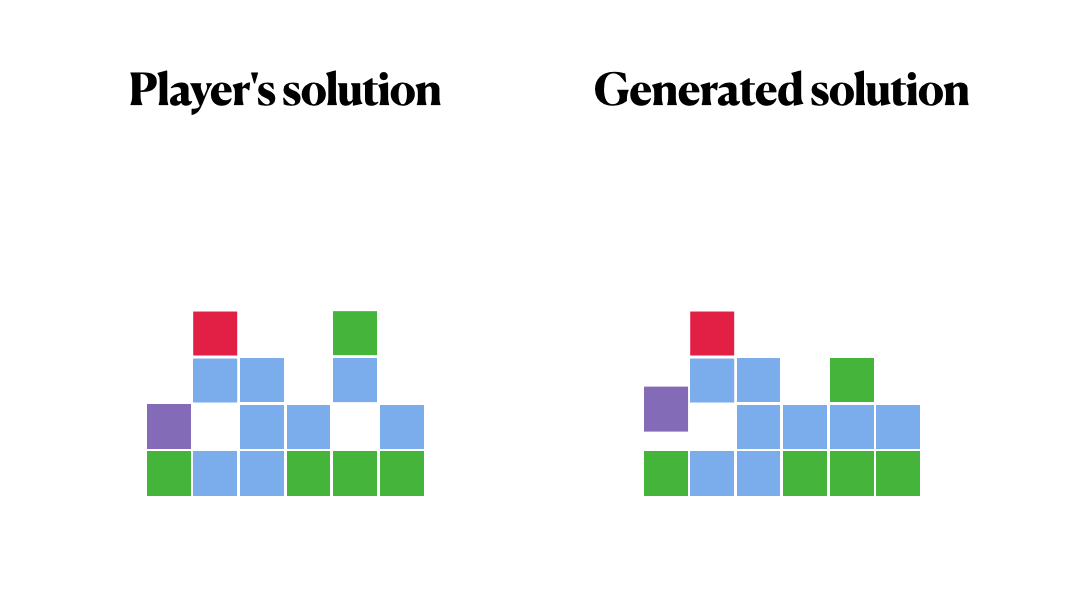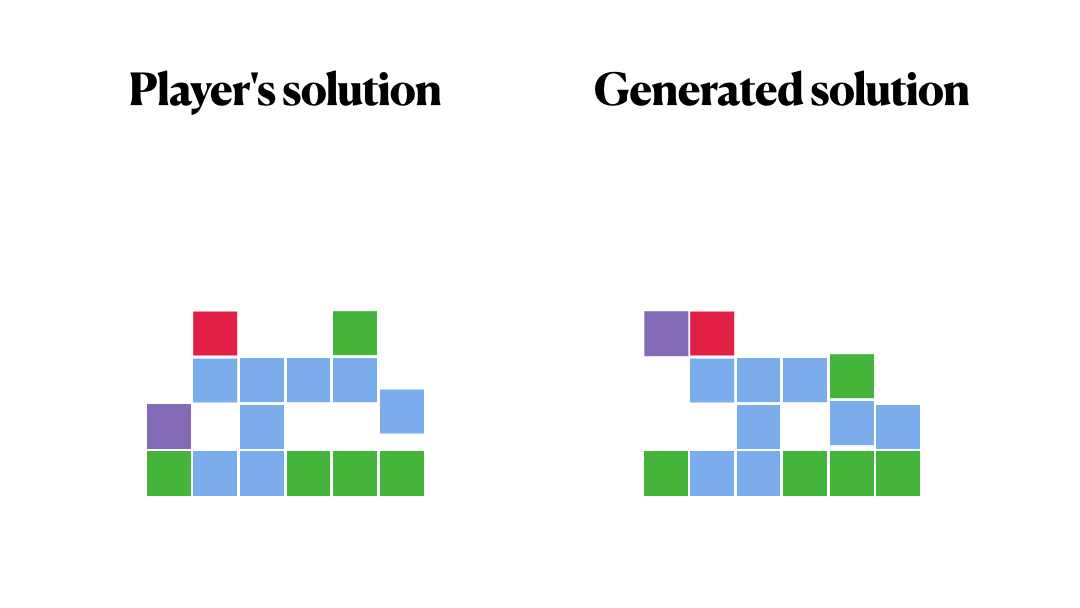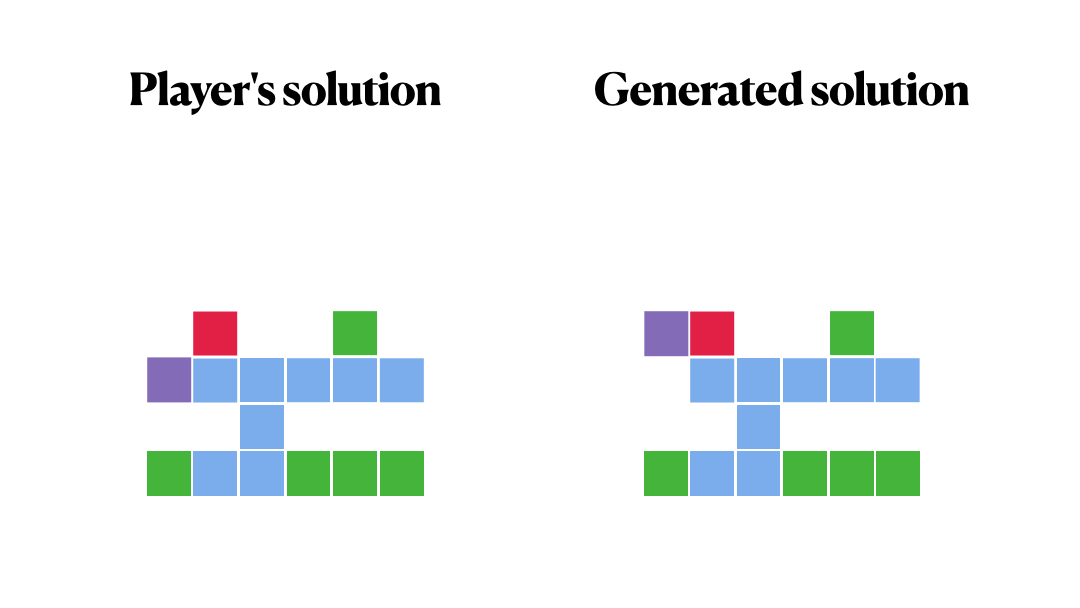
It makes sense, right?
Next, we plan to analyze the obtained solutions, optimize the search for the optimal policy, analyze the sorted steps, and see how shuffled data affects agent learning. Stay with the Borderlands Science team and see if you can borrow a strategy from the very best players!